
Why Is It Important to Link Precision to Your Risk Appetite
Apr 11, 2023
Daan T. Bakker

Why it’s important for insurance carriers to link precision (often called hit rate) to their risk appetite? Simply put, if they don’t, they will later miss out on important intelligence. Here’s how to find the right balance between your right hit rate and your risk appetite:
Setting the stage for 100% precision
Let’s start with some words we use to correctly classify fraud:
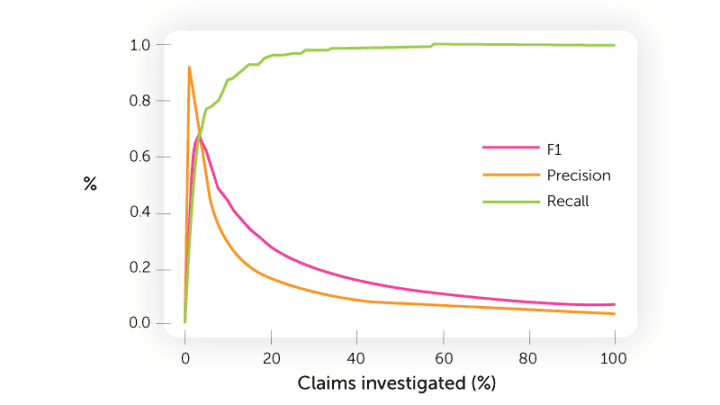
F1: two times precision times recall divided by precision plus recall
Precision: the number of correctly classified claims divided by the total amount of claims returned
Recall: the number of correctly classified claims divided by the total amount of fraud cases in a historical dataset
Our recent insurance fraud study shows that insurance professionals believe 18% of claims contain an element of fraud. If you look at a set of 200,000 claims, there will definitely be some fraud to be found. If you classify only one case, with the assistance of a fraud detection model, you might find only the most obvious one. From a data science perspective we say there’s a 99.9% probability this is a fraud case. The precision (or hit rate) would in this case be 100%. Now that’s a success rate any claim adjuster would love to bring back to his manager.
Keep an eye on the honest customer
Why wouldn’t you want this? In the above example, the majority of fraudsters would pass through the cracks. Because while there’s 100% precision and we believe most fraud is classified, in reality, only 1 out of 200,000 claims was flagged by the system.
If you want to catch all fraud, you need to classify all 200,000 claims. This would enable a zero-tolerance strategy, but the special investigations unit would be flooded with false positives. Since the vast majority of customers are good customers, they deserve speedy payment without unnecessary delays from the SIU department.
In order to make a decent selection for further investigations, you must be more selective in classifying fraudulent cases.
Finding the right balance
That’s why we believe it’s vitally important to work together with our customers to balance precision with risk appetite. Our powerful AI techniques such as predictive models, network analysis, and text mining, combined with over 600 out-of-the-box risk and fraud indicators, can automatically flag any kind of potential fraud.
If there’s limited SIU capacity, we tune the system to a higher precision so that only the riskiest cases are flagged for further investigation. If there is sufficient capacity and decent processes are in place for following up on alerts, you want a lower precision and higher recall.
Investigating more claims also means that our models get more feedback from the SIU department. This feedback automatically re-trains our models, ultimately leading to higher precision. This is a positive feedback spiral, and benefits our customers’ fraud detection rate greatly. Finding the balance between precision and recall is what’s most valuable for our customers.
This is the challenge our data scientists take on daily when implementing FRISS, and I personally take a lot of satisfaction in doing this right. Besides bombarding my colleagues with terrible music jokes that is…